Mobile Development
A primer on Hybrid Mobile Applications 
Ganesh Akondi 17 Nov, 2016





AI/ML are now essential to businesses to deliver value to customers, optimise decision making and to provide a clear edge in a competitive landscape. As the advances in core AI/ML technology becomes more and more available and consumable it is apparent that organisations need to leverage this for themselves at a faster pace.
Today in almost every domain that we can think of AI/ML can help solve some of the intractable issues which couldn’t be solved earlier. With the advent of machine learning frameworks and libraries, it is easier to build AI/ML solutions than before.
Given these advances, organisations and their stakeholders realise that they need to embrace AI/ML. The importance of having successful AI/ML outcomes will catapult an organisation in to the next growth phase or even create new lines of businesses. But even as organisations invest in more resources in AI/ML projects, executives are not realising the anticipated return on investment. The reality has not caught up with the hype around this.
The reason is a less than ideal AI/ML workloads where people involved are working with many disconnected tools. They are grappling with data management tasks, infrastructure, configuration, lack of first-class engineering support, and most importantly to operationalise the output to deliver business value.
As a consequence of the above, most AI/ML projects start with great fanfare (as it is frequently a C-Level executive initiative) and then peters down as it makes its way through the ranks. By the time organizations realize it, the budget is spent on hiring expensive resources, costly infrastructure and developing disjointed and disconnected artefacts with no viable output for delivering end to end business value.
Most AI/ML projects fail because of three primary causes: Reproducibility, Leveragability and Scalability
Generally, data scientists gather data and do their work in an environment that is on their local machines, or on code notebooks (offline or online). Since in AI/ML, experimentation is a first-class citizen, its journey starts as ideas and code put together in an unstructured way. The consequence is that it is not reproducible, repeatable or scalable. The results have
no guarantee of dependability and are stochastic in nature. Even if it did show some exceptional results in the experimentation phase, it is not in a state to be used by line of business units.
Leveragability
Most AI/ML workloads cannot be completed by a single person. It has many parts to it. Each with a different skillset and experience requirements. One cannot leverage the work done by an upstream team (for e.g. data curators) by downstream teams (for e.g. data scientists, feature analysts etc). Not only are different skills in play, they are also disconnected. Coupled with the inherent non-reproducibility, it only exacerbates the leveragability problem.
Scalability
If we successfully navigate the above two causes of failure, we run into the issue of scaling the output to serve customers at scale. Typically say everything works out in development and staging, that is saying a lot. But when we get to production level scenarios, it fails as it reaches the limits of scalability required for actual business scenarios.
Aside from the above three primary causes there are seven other concerns which impede the operationalization of AI/ML workloads.
A typical AI/ML workload has the following major components: Data, Feature Engineering, Model Training and Generation, Model Serving and an Application which consumes the predictions for delivering a business value.
Each of the major components can be further subdivided:
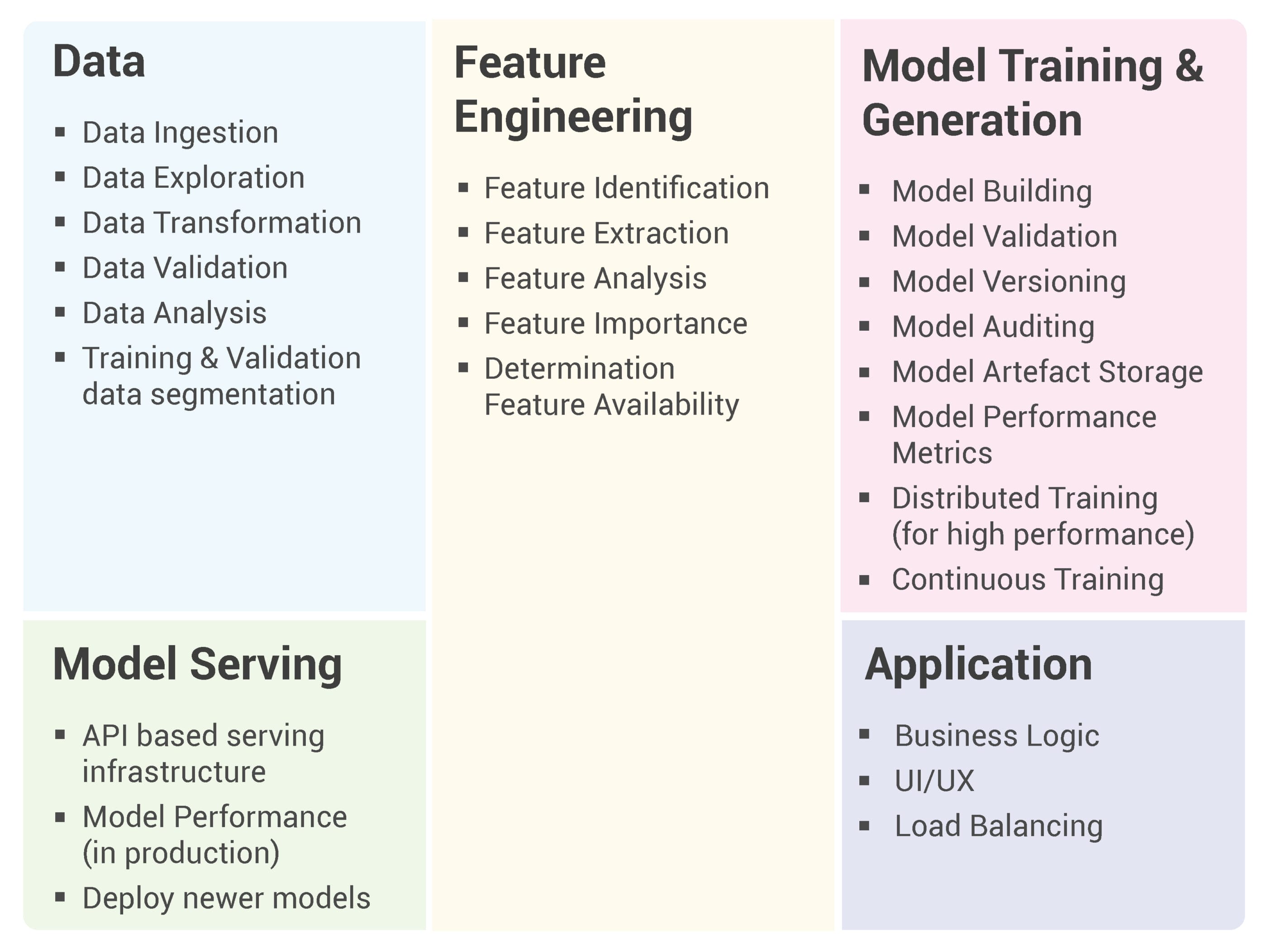
As you can see there are a lot of tasks that need to work individually and together to enable a successful outcome for the AI/ML project. A common scenario is each of these will be performed a different team with disparate skillsets and experience.
Another thing to note is most current AI/ML workload planning concentrate only on model training, validation and generation. The rest of the components are an afterthought or at best implemented in an ad-hoc manner which can neither be reproducible, leverageable or scalable.
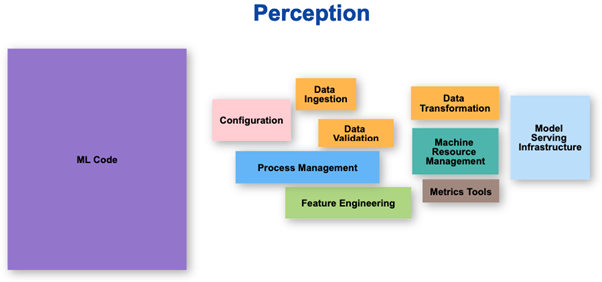
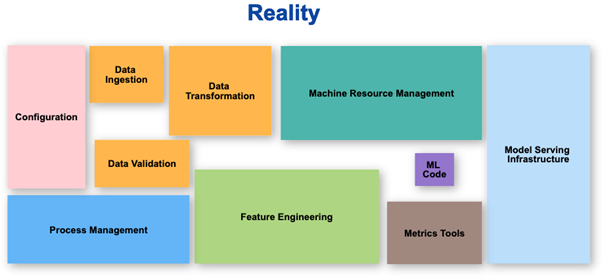
The part which the ML team focuses on is at best 10% of the overall work that needs to be done in a structured manner. The perception is most of the work is ML code, but the reality is actually quite different.
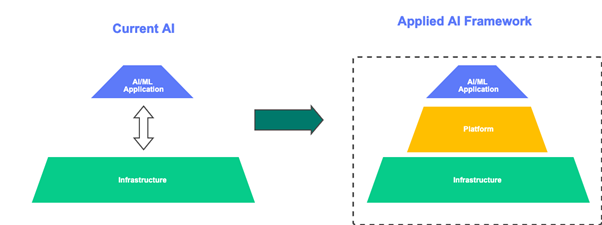
Applied AI is needed to develop, manage, deploy and match real-world AI/ML workloads end to end.
Applied AI is a framework that has a compatible set of tools and artefacts that enable one to operationalize AI/ML workloads from experimentation to production level applications. Its aim is to address most of the issues that cause AI/ML Project failures.
Currently, we write AI/ML applications and launch it on cloud or on-prem infrastructure. But the missing link is the ML platform that mediates between the application and the infrastructure. The framework that ties and integrates all these three, comprises an Applied AI framework.
A fundamental part of Applied AI framework is composability of components using Pipelines. A pipeline can be configured (even visually) where the output from upstream components can be seamlessly configured to be input to downstream components. Since composability is built-in, each component can then be reused and combined for multiple AI/ML projects. This addresses the leveragability issue inherent in the traditional way of developing AI/ML projects.
Another major feature is the ability to abstract the infrastructure layer such that we can deploy the same workload (with minimal changes) on the various cloud platforms (AWS, Azure, GCP etc) or on-prem infrastructure or hybrid infrastructure. This helps with scalability and coupled with infrastructure resource management enables a highly performant application. Ability to run multiple experiments, model versioning, auditing and capturing model meta data ensures reproducibility and tracing.
Now that we know why and what is Applied AI, we can now describe how do we go about implementing Applied AI. As such there are some preliminary phases (and milestones) that need to be completed.
First is the Discovery & Definition phase. In this phase, we have 6 milestones that need to be achieved: Project Kickoff, Data Landscape, Process & Technology, Business Use Cases, Skills Landscape and AI Strategy.
Project Kick-Off
Data Landscape
Process & Technology
Business Use Cases
Skills Landscape
AI Strategy
Next Is the Proof of Value phase. In this phase, we take the outputs from the Discovery and Definition phase (especially in terms of data, use cases, resources and strategy) and create
a list of prioritised initiatives which can then be allocated to respective teams for fulfilment.
The heart of any Applied AI framework is the concept of “Pipelines”. Where in we can chain various tasks together to achieve composability. Here is a list of frameworks which are
currently popular:
Apache Airflow : (https://airflow.apache.org/)
MLFlow : (https://mlflow.org/)
Kubeflow : (https://www.kubeflow.org/)
Out of these three, MLFlow and Kubeflow are specialized platforms for AI/ML lifecycle while Airflow is more of a general-purpose workflow platform.
Once the selection is made the infrastructure should be set up for launching one of these frameworks. Then the pilots identified in the Discovery and Definition phase need to be implemented. By doing two pilots as opposed to one, it forces one to handle a variety of organizational scenarios in terms of resource partitioning, security, domain expertise etc.
While all of these tools and frameworks have different foci and strengths, no one thing is going to give you a headache-free process straight out of the box. Before struggling over which tool to choose, it’s usually important to ensure you have good processes, including good team culture, blame-free retrospectives, and long-term goals.
Conclusion
In conclusion, we see that starting directly with AI/ML applications is prone to fail. Here we described a process and methodology that will consistently deliver value while managing the complexity inherent in implementing AI/ML workloads at scale in enterprises.


