Outsourcing & offshoring
Balanced Sourcing in Software Offshoring Kiran Madhunapantula, COO 30 Jan, 2014





Event sourcing is a design pattern, in which changes to the state of an application are stored as sequence of events and stored in an event store. Later by executing these events we can build the current or previous state of the application. We do not perform any update, delete operation on the data. Let’s look at a typical event sourcing design.
A typical event sourcing model consists of a Read/Write API.
Write API instead of writing to the database, it creates events & they are persisted to an event store, whereas Read API reads from the same event store & generates the current state by executing the events. Event Sourcing enables gradual building up of the application architecture by addition of new read applications that process the same events from event store & display in different views.
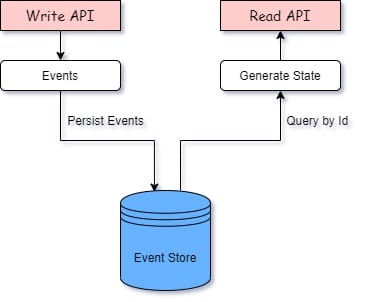 Let us consider the following example:
Let us consider the following example:There is a person who goes to a bank, opens his account, and makes some deposit and withdrawal operations over few months.
In a traditional data-centric approach, design would have consisted of a few databases tables & we update the tables each time a deposit or withdrawal is made. However, with event sourcing, we do not perform any operation on data, instead we create an aggregate by storing each operation as a sequence of events in an event store like Cassandra or mongo DB. We can create current state & have complete history of the person. Here events names are Verbs as they happened in the past, and generally we derive the name from the domain in which we are working.
Below is the sequence of events stored in the event store for the banking example:
| AccountCreated | 435266 | Test Name | 10-10-2019 13:59:10.0 | ||
| DepositPerformed | 435266 | $300 | 02-01-2020 11:02:13.0 | ||
| WithDrawalPerformed | 435266 | $250 | 09-01-2020 13:05:25.0 |
| AccountCreated | 435266 | Test Name | 10-10-2019 13:59:10.0 | ||
| DepositPerformed | 435266 | $300 | 02-01-2020 11:02:13.0 | ||
| WithDrawalPerformed | 435266 | $250 | 09-01-2020 13:05:25.0 | ||
| WithDrawalFailed | 435266 | $1000 | Insufficient funds | 14-01-2020 10:00:21.0 |
| AccountCreated | 435266 | Test Name | 10-10-2019 13:59:10.0 | ||
| DepositPerformed | 435266 | $300 | 02-01-2020 11:02:13.0 | ||
| WithDrawalPerformed | 435266 | $250 | 09-01-2020 13:05:25.0 | ||
| WithDrawalFailed | 435266 | $1000 | Insufficient funds | 14-01-2020 10:00:21.0 | |
| DepositPerformed
| 435266 | $1200
| 10-02-2020 15:00:39.0 |
This is our event store and it grows over a period of time by storing all the changes as events. Read side can query this store and construct the latest state.
Command Query Responsibility Segregation (CQRS) is a design pattern that segregates the responsibility of reading and writing to two different models in application. The application is split into two parts Command-side that commands a system to perform write operations & Query-side that queries the saved state. It also provides separation of concerns as Command & Query does not care what another model is doing. An event handler takes care of publishing events to the read-side from write-side. Apache Kafka is a popular messaging service that implements CQRS very effectively.
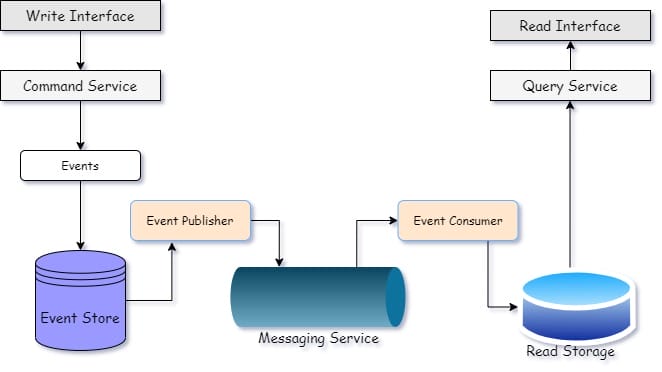 Why CQRS??
Why CQRS??As we know CQRS provides separation of concerns, the command /write side takes care of business logic irrespective of the query model; and the query-model is responsible for how fast it can retrieve stored data, and optimization irrespective of the write-model.
The load gets shared between the two models and write & read side can individually scale as per need. Application can contain a single write & multiple read models, and each read-side model can process same events & display them in different views.
While upgrading, we can add a new read-side model without any downtime, and we can also easily revert to a previous state in case of an error & recover soon. This makes the application stable, resilient & better in terms of performance.
CQRS & Event sourcing are generally used together along with Kafka.
Pros:
Cons:
Event sourcing with CQRS allows applications to store their state in the form of events in event stores. With this architectural pattern, applications are loosely coupled, resilient, and there is minimal risk of downtime and they can be scaled up as needed. While a simple CQRS implementation can yield good results without introducing complexity, if not designed properly, it may also result in increased complexity & unmaintainable code. Kafka is not a must have for Event Sourcing or CQRS, even though the designs that use Kafka can leverage its core benefits such as performance, reliability, and zero-fault tolerance.


