
Uncategorized
Search Xebia Blogs : Firefox Plugin 
Vikas Hazrati 20 Sep, 2007





Our previous post on Lucene highlighted various positive aspects of lucene. Now, let’s delve into how lucene was used in a distributed environment.
We discussed retrieving all required data from lucene index itself or alternatively using the hybrid approach of querying lucene first and then the database. Within our business needs, we did not prefer the first approach for several reasons, which are:
NoSQL in place of the hybrid approach would have been a better case. Since NoSQL uses Lucene indexing for document storage, we won’t need database layer and we could store, query and search all data within NoSQL.
Using NoSQL for our business needs was not possible due to various architectural reasons as we work on a network of applications and systems with lot of bi-directional data flow between various applications on various platforms.
We are now restricting the use of lucene indexes to freetext search because of the updated and complex security model across different applications in the system. This security model requires the application to access database before forwarding the data to users, in this scenario, the hybrid approach would more or less have similar performance as database-only approach. Freetext search is the only part where lucene proved its worth in our current business scenario.
I am sure that it can be used in other scenarios considering how NoSQL is becoming more and more mature, stable, feature-rich and accepted.
Distributed environment
Distributed environment was needed to support the global organizations of Unilever with main servers in UK and Netherlands.
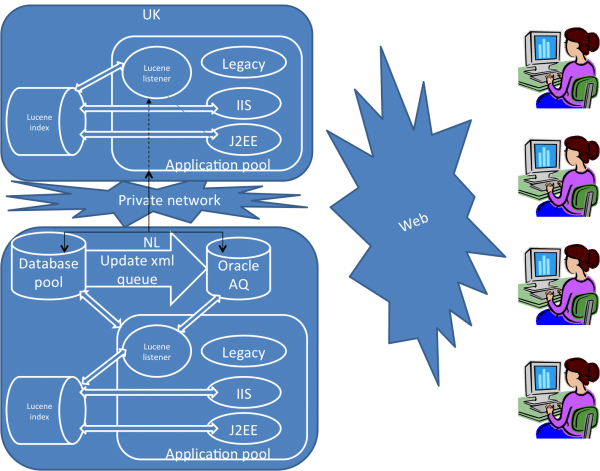
Database pool is at one location with different database servers for different applications, but with links where data sharing is required.
Application pool holds different applications on different technologies or platforms sharing the database pool.
Lucene index holds indexes required for specific applications, it is possible for the same index to be shared by different applications even across different platforms like Java and .NET.
Oracle AQ is an advanced RDBMS based queue system which holds messages for updates to database. Messaging system is used to update the lucene indexes, RAM data caching, notifications, subscription mails, etc… We decided to use Oracle AQ instead of other messaging solutions like MSMQ due to its robust and secure support for use in distributed environment. We were not satisfied with non-database messaging solutions in distributed environment especially with the fallback mechanisms it can offer when system is down or memory is corrupted.
Architecture
As the diagram shows, the two server locations are connected through high speed private network with database pool in one location and load balanced application servers at both locations.
Database triggers
Database updates raises a trigger that enqueues XML message of the updated data into Oracle AQ
Duplication of lucene index
Lucene index is duplicated at both locations because using a single NAS (Network-attached storage) to store the index was sometimes unavailable or encountered locking issues when writing from multiple servers. Since Oracle AQ was used for multiple consumer, we calculated that it took same amount of work to have duplicate indexes on application servers instead of on the NAS.
Listeners
The listening threads of applications would check the queue for any new XML messages and processed by intended consumers. The index listener would process the update index message from queue and update the lucene index. The two servers are registered with Oracle AQ for reading the queued messages, the messages are dequeued if all consumers in both servers have finished processing the message. Failures will either re-queue the message or moved to dead queue.
Application
User requests are load balanced in two servers, first request from a user maybe processed by one server and the subsequent request from the same user maybe processed by another server in the same session. This required us to maintain session in database for robust and scalable factors.
Application requests for search will perform a search on the corresponding lucene index and query the database pool for required details. RAM cache is used for simple data retrievals, Lucene index is used for advanced search and filters.
Analyzer algorithms
For tokenized fields, we used StandardAnalyzer or WhitespaceAnalyzer and for untokenized fields, we used PerFieldAnalyzerWrapper with the default analyzer as well as KeywordAnalyzer in it. Using PerFieldAnalyzer will help in cases where different fields require different analyzing techniques, ex: for exact match or keyword searches, KeywordAnalyzer is used. We used ComplexPhraseQueryParser to parse the search string as we supported complex query terms.
My memory fails me on the details of how different algorithms were used at the beginning, what type of issues arose and how the currently used algorithm resolved them, but the fact is that lucene and NoSQL will grow in strength and features and become more acceptable to improve our application performances.

